
- Tech Note: Vapor: Simple automatic deployment using Docker and GitLab CI
-
Do you use Apple Music or iTunes, enjoy listening to entire albums but struggle to find them in your library? Then join the beta of my upcoming app, Longplay. It’s quite pretty, too!
- Tech Note: Using Carthage in a Catalyst app
-
2019: ‘The Shining’ starring Jim Carrey
2025: Facebook lets you watch your favourite movie with a cast of your friends.
-
With the upcoming custom inputs and outputs in Shortcuts on iOS, I hope that someone will make HTTPie and jq for iOS. That would make working with APIs in Shortcuts a lot easier.
- Tech Note: iOS 13 toe-dipping: Multi-window support on iPad
-
Framework Sherlocking at WWDC 2019
WWDC is lovingly referred to as “Christmas for Apple Developers” and, goodness, was it a Bescherung this year! Apple has been hitting it out of the park at this year’s WWDC. While in the past many developers have been worried that their apps were getting replaced with Apple’s own new or improved apps (aka “Sherlocking”), a big surprise of this year is how many third-party libraries and tools now have first-party replacements1:
- Declarative views: CvlView → SwiftUI
- Building forms: Eureka → SwiftUI.Form, via @kuba_suder
- Reactive programming: RxSwift or ReactiveCocoa → Combine
- Reactive table/collection data sources: RxDataSources → diffable data sources
- Cryptography: CryptoSwift → CryptoKit
- Dependency management: Carthage → Swift Package Manager right in Xcode
- Icons with custom weights: PaintCode → SF Symbols
Granted, none of these are complete replacements2, and developers cannot rely on all those first-party replacements yet either (as most of them require iOS 13), so these third-party frameworks and tools still have reason to exist.
I am very excited about this. It’s not changing what you can do, but how you can do it. As Brent Simmons puts it nicely, it is the start of a new era, which is significant as the previous era has been going for close to thirty years.
It is great that Apple is modernising the frameworks and giving declarative and reactive programming the first-party treatment, learning from what both the Apple developer community and other platforms are doing. Having Apple throw their support behind these concept will likely accelerate and improve them further, too. SwiftUI in particular has tremendous potential — not just for Apple platforms. Might I dare ask how much effort would it be to generate an Android app from a SwiftUI code base? Though, unlike Swift itself, SwiftUI and Combine are not open source (yet?).
Developing for Apple in the 2020-ies will look much different than it does now. Exciting times and a lot to learn!
-
These are only the ones that I’m familiar with and that stood out to me in the subset of videos that I watched. There’s likely even more. ↩
-
See for example this comparison of Combine vs. RxSwift. ↩
-
Kudos to Becky Hansmeyer for the timely reminder that this year will likely be the first year for many iOS developers that they will want to run macOS betas. Be prepared, backup and keep a stable install handy.
-
Next steps for Siri, and other WWDC 2019 wishes
Apple’s annual developer conference, WWDC, is just around the corner. As a developer of iOS apps and heavy user of macOS, this is always an exciting time of the year. There is talk about iOS apps being able to run on macOS and dark mode coming to iOS. Before I get busy with implementing these from next week on, it’s fun to take a step back and think about what I would like to see Apple do and let developers do. I’ll start with my hopes for Siri, and then more wishes from a more (power) user perspective and then from a developer perspective.
Make Siri a pro-active productivity assistant
Siri as a voice assistant is not overly exciting to me personally1. I use it mostly for simple things like setting timers and reminder, occasionally controlling my music, checking the weather, turning on my coffee machine and checking the battery of my car; but for most other things I turn to using my hands and having visual interfaces.
However Apple is making Siri slowly into more than a voice assistant; turning it more into a pro-active assistant that knows what you do when, and then gives you help by itself before you explicitly ask for it. This I find very exciting. So far Apple has only taken little initial steps down this path like predicting what app you’ll use next, or what location you’ll go to next and telling you traffic going there2. Exciting is what else Apple could do with this and what developers could do with it once Apple opened up these predictions.
From apps to actions
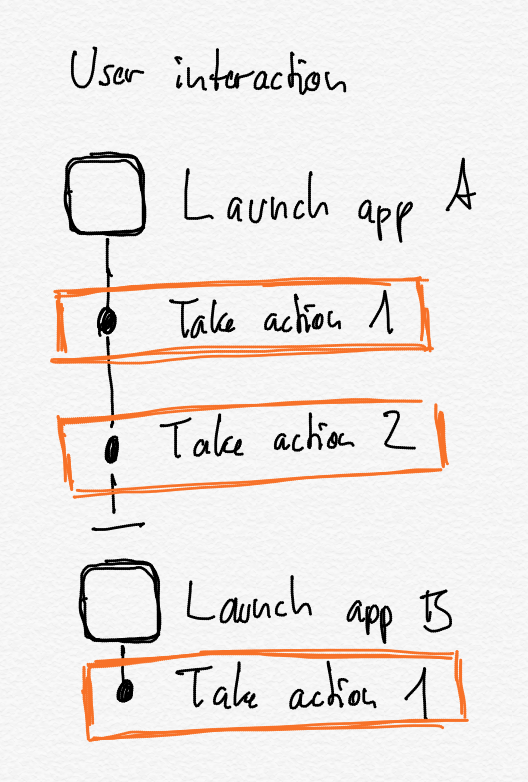
At WWDC 2018, Apple introduced Siri Shortcuts, which brought automation capabilities to iOS by letting developers expose what individual actions a user is doing in their app back to the operating system and also when the user’s are doing them. This enabled two things:
- Users can create short voice commands (so called Siri Shortcuts) for often used actions which then can run by themselves without launching the app, or open the app directly on the relevant section in the app.
- iOS can predict not just what app you’ll use next, but also what particular action you’re most likely to do next and suggest this.
The first of these was a great way forward for automation on iOS, especially in combination with the Shortcuts app that let’s users string together individual actions — just look at the iOS automation content on MacStories, the Automators podcast, and the many examples on Sharecuts. And I very much hope that Apple iterates this by allowing app developers to make those actions dynamic by letting users specify inputs and handle outputs coming from them.3
The second could be really interesting,4 when you consider that Apple could not just predict individual actions but also sequences of actions — including spanning multiple apps or even across devices5. In essence, Siri could learn repetitive actions that you do, and suggest entire multi-step Shortcuts for you to run, which you then can also customise further. This could be a great way to get people into Shortcuts and automation in general!
Let developers enrich the Siri assistant
My second wish related to a pro-active Siri is that Apple opens up the predictive smarts of Siri. It would be fantastic, if developers could, say, get access to predictions for your next destination (and departure or arrival time) or a contact you’re likely to interact with. Currently developers have to track you in the background or figure this out themselves by looking at your past usage of their apps.
Tapping into Siri’s predictions through an Apple-provided interface, would have several advantages:
- This could be done in a privacy-conscious way that keeps the user in charge, where the user could have controls over what is shared with what app.
- There could be a central way for users to redact predictions or past usage patterns, like you can currently do for locations in the Settings app under Privacy > Location Services > System Services > Significant Locations.
- Users would get more consistent experience across apps that use (or predict) this data, as well as across devices.
- Developers more easily integrate predictions into their apps.
I would love to work with these predictions and see what other developers would come up with.
Lastly, here’s an unordered grab bag of my other wishes:
User prespective
- Sharing of iCloud Drive folders not just individual files
- Shared Photo libraries for families
- Shortcuts for macOS
- Schedule a Shortcut to periodically run in the background
- Any improvements on iPad to multi tasking, window management, search and keyboard support would be appreciated
- A MacBook with a durable keyboard
Developer perspective
Developer tools on iOS:
- Xcode on iPad, so that I can only take my iPad to short trips and still be able to do some development work. I’m fine if it’s limited to a smaller feature set or Swift-only, as I don’t intend to write a full app on the iPad but would be great to work on some isolated features. Swift Playgrounds is a start but still a playground; I really want to have proper access to my projects and source code6.
- Terminal on the iPad, including being able to use homebrew.
SDK improvements:
- Share links for iCloud Documents, not just temporary snapshots but permanent and pointing to the same copy; just like iWork already gets it.7
- UI components for the card-based UIs that Apple is using in its Maps and Music apps.
- Using UIKit on the Mac and being able to mix it with AppKit
- That declarative UI framework
- Async/await in Swift
Fingers crossed, and here’s to exciting announcements. Happy WWDC to anyone attending!
Update from 13th June: The results are in
Siri + Shortcuts improvements:
- ✅ Allow app developers to create Shortcuts actions with dynamic inputs and outputs
- ✅ Shortcuts app to suggest Shortcuts based on how you use your device usage
- ❌ Provide an API to Siri’s predictions
- ❌ Shortcuts for macOS: Though Steve T-S is on it
- ✅ Schedule triggers for Shortcuts
User perspective:
- ✅ Sharing of iCloud Drive folders
- ❌ Shared Photo libraries
- ✅ Improved iPad multi-tasking and window management
- ❌ MacBook with a durable keyboard
Developers perspective:
- ❌ Xcode on iPad
- ❌ Terminal on iPad
- ❌ Public links for iCloud documents
- ❌ UI components for card-based UIs: No, the new sheet persentation style isn’t that
- ✅ UIKit on the Mac and mixing it with AppKit: Catalyst + AppKit
- ✅ Declarative UI framework: SwiftUI
- ❌ Async/await in Swift
Things I didn’t know I wanted:
- ✅ A first-party framework for reactive programming: Combine
-
It’s not helping that Siri is lagging behind Alexa and Google Assistant. ↩
-
Which isn’t particularly useful when you mostly get around by public transport, cycling or walking. ↩
-
As of iOS 12, the actions that third party apps provides are basically dead-ends. As a user, you cannot, say, get the cycling duration to work from Komoot, pass that duration to your favourite weather app, take the forecast, and then have the shortcut tell you whether to cycle or maybe better take public transport (or your rain gear). ↩
-
Though Apple so far hasn’t delivered much on this yet. In close to a year of iOS 12 usage (including betas) I have never seen any of these action suggestions on any iOS device. They do come up occasionally on the Siri watch face on my Apple Watch, but for me are mostly useless suggestions such as start timers of inappropriate durations or toggling HomeKit scenes that rarely match the one I want to trigger. ↩
-
Highlighting your inner procrastinator by predicting that since you’ve just closed twitter.com client on your Mac just a moment ago, now is a good time to open your favourite Twitter client on your iPhone. ↩
-
This makes me wonder if Xcode on iPad could being serious competition to Working Copy. ↩
-
Plus my list of radars related to sharing UIDocument from January this year. ↩
- Tech Note: Keyboard shortcuts and the iOS responder chain